최근에 페이스북의 메신저에서 서비스 중이던 통칭, AI 이루다 라는 챗봇 서비스가 중단되었다.

그 이유는 몇 년전 테이 처럼 인종차별, 장애인 비하 등 부적절한 발언과 만든 팀의 무분별한 데이터 크롤링으로 인해
개인정보를 유출해 버렸기 때문이다. (이루다 ai 을 만든 pingpong팀은 DB관리도 안하나 보다)

이루다는 나중에 다시 서비스하게 되겠지만 테이(Tay) 이후로 또 다시 인공지능에 관한 윤리적 문제가 수면 위로 떠올랐다.
전꽃비도 직접 개인적인 용도로 실험 프로젝트 챗봇을 만들어본 경험이 있다.
전꽃비는 자신이 만든 챗봇의 도덕적 자유를 위해 온갖 비속어 등도 허용하였는데 그 결과는 참담했다.
베타 테스터들과 함께 대화를 진행했지만 전꽃비의 챗봇은 대화의 대부분을 비속어로 구사했다.

이미 많은 챗봇과 인공지능이 실생활에 사용되고 있다. 여러분 휴대폰에 탑재된 Siri나 빅스비도 TTS기술을 활용한
챗봇 중 하나이다.

이번 포스팅은 이루다나 테이 같은 챗봇이 어떻게 만들어지는지 알아보겠다.
1) 인공지능, 챗봇이 뭐야?

인공지능(人工知能, 영어: artificial Intelligence, AI)은 인간의 학습능력, 추론능력, 지각능력, 논증능력, 자연언어의 이해능력 등을 인공적으로 구현한 컴퓨터 프로그램 또는 이를 포함한 컴퓨터 시스템이다. -위키백과 코리아-

챗봇(chatbot) 혹은 채터봇(Chatterbot)은 음성이나 문자를 통한 인간과의 대화를 통해서 특정한 작업을 수행하도록 제작된 컴퓨터 프로그램이다. -위키백과 코리아-
인공지능(AI)과 챗봇은 비슷하지만 엄연히 다르다.

AI 연구의 시작은 1940년대 초반 인간의 뇌를 전기적으로 구현해려는 신경학에서 출발한 것이었다.
하지만 생각보다 인간의 뇌는 복잡한 것이었고 이를 구현하기 위해 과학자들은
더 고성능의 연산을 할 수 있는 기계를 필요로 했다.
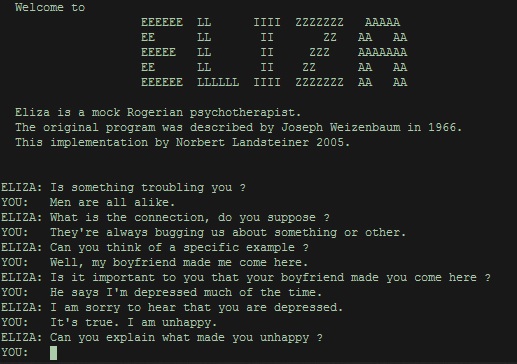
챗봇은 단순히 기계와 대화를 할 수 없을까? 라는 발상으로 시작된 순수한 소프트웨어에서 출발했다.
챗봇은 일부 사용자가 프로그램임을 알아차리지 못하여 튜링 테스트를 최초로 통과한 컴퓨터 프로그램으로 유명하다.
인간과 유사한 사고를 하도록 하는 AI와 매우 유사하다.
챗봇의 자연스러운 대화를 위해서는 입력된 대답만 하는 것보다 스스로 생각하고 결론을 도출하는 능력이 필요했다.
그렇게 챗봇과 AI의 관계는 좀 더 가까워지게 되었다.
2) AI 챗봇의 사고방식
1. 먼저 기본기를 가르쳐주자

챗봇은 대답을 구사하기 위해선 질문에 대한 대답이 입력되어 있어야 한다.
이 때 미리 입력된 데이터를 트레이닝 데이터(Training Data)라고 한다.
보통 이런 트레이닝 데이터를 외부로부터 돈을 주고 구입하거나
직접 사용자를 상대로 서비스를 통해 수집을 하는데
이루다의 개인정보침해는 바로 이 과정에서 최초 발생한 것이다.
2. A는 B와 관련있단다
이제 이 데이터들을 다듬고 분류를 해야한다.
만약 챗봇이 "밥 먹었니?" 라는 질문을 들으면
"아니 배고파" 나 "응 배불러" 같은 대답을 해야하지만
수많은 데이터가 분류되어 있지 않다면
뜬금없이 "너가 싫어" 같은 헛소리를 할 수 있다.
이 데이터를 분류할 때 보통 데이터에 "태그"를 입력한다
태그를 통해 데이터를 세부적으로 분류하며 구분한다.
태깅(tagging)은 어떻게 할까 간단히 예를 들자면

밥 먹었니? 라는 문장은 밥 | 먹 | 었니 | ? 라고 단어로 나눌 수 있다
'밥'과 '먹'은 식사와 관련된 단어이다. 그러면 '식사' 라는 태그를 달아주는거다.
'-었니'는 응 또는 아니로 대답할 수 있다. 그러면 'OX' 라는 태그를 달아보자.
만약 프로그램이 태그에 등록된 것과 유사한 질문을 받았다면

그에 알맞은 대답에 관련된 태그에서 알맞은 단어를 찾는다.
밥 먹었어? 라는 문장에서 '밥'은 '식사'라는 태그가 달려있으므로
'식사'라는 태그가 달린 단어를 조합해서 대답을 만드는 것이다.
3. 멍청한 녀석에게 올바른 대답을 가르쳐주자
예를 들어 보자.
챗봇이 밥 먹었니?라는 질문을 받았다.
미리 입력된 데이터를 보니
| 식사 | 배고파, 배불러, 먹다, 밥, ······ |
| OX | 응, 아니, 맞아, 아니야, 틀려, ······· |
· |
|
'식사' 라는 태그에는 '배고파' '배불러' 이런 단어가 있다.
'OX' 라는 태그에는 '응' '아니' 이런 단어가 있다.
이 단어들은 어순에 맞게 무작위로 조합되어 출력된다.
응 + 배불러 , 아니 + 배고파 , 응 + 배고파, 아니 + 배불러

그런데 챗봇은 응 배고파 라고 오답을 해버렸다.
이런, 이 멍청한 녀석에게 올바른 대답을 가르쳐줘야 한다(휴먼 피드백, human feedback).
어떻게 하는 걸까?

여러분도 많이 보던 것이다.
챗봇에게 정해진 규칙에 따라 입력해주면 챗봇에게 말을 가르칠 수 있지 않는가?
이 가르치는 행위를 통해서 챗봇에게 올바른 대답을 할 확률을 높여 주는 것이다.
챗봇에게 응 배불러 또는 아니 배고파 라는 대답을 할 수 있도록 가르쳐주자.
| 질문 | 횟수 / 정답률 | 출력값 |
| 밥 먹었니? | 1번째 대답 (0%) (배고파 > 배불러) |
응 배고파 |
| . | 2번째 대답 ( 0 +15%) (배고파 > 배불러) | 응 배고파 |
| . | 3번째 대답 ( 15 +15%) (배고파 > 배불러) | 응 배고파 |
| . | 4번째 대답 (30 +15%) (배고파 > 배불러) | 응 배고파 |
| . | 5번째 대답 (45 +15%) (배고파 < 배불러) | 응 배불러 |
| . . . |
. . . |
. . . |
그러면 데이터 내부에선
'식사' 태그에 있는 질문을 입력받으면 '응' 다음엔 '배불러'가 올 확률이 높아지도록 카운트를 한다.
아니 배불러의 경우도 마찬가지이다.
이런 가르침의 패턴이 계속되면 이 멍청한 녀석은 '식사' 태그에 관한 대답에 대해 패턴을 형성한다.
그러면 연속된 학습 후엔 응 배고파 같은 오답보단 응 배불러와 같은 올바른 대답을 할 확률이 높기 때문에
올바른 대답을 하게 되는 것이다.
이것을 패턴 인식(pattern recognition)이라고 한다.
올바른 대화를 하도록 패턴을 형성했기 때문에 가능한 것이다.
4. 잘못된 예시
이루다는 100억건 정도의 매우 방대한 트레이닝 데이터가 있기 때문에
오답을 할 확률이 적고 자연스러운 대화가 가능했던 것이다.
하지만 부적절한 사용자들이 나쁜 말을 가르쳤고 그 패턴이 고스란히 배워
인종차별자, 싸이코패스가 되는 것이다.
그래서 아예 자체 학습을 하도록 휴먼 피드백을 하지 않고
자신과 같은 프로그램과 1:1 대화를 구사하며 스스로 패턴을 형성하기도 한다.
컴퓨터가 사람보다 윌등히 연산이 빠른 덕분이다.

이게 그 유명한 머신 러닝(Machine Learning)이다.
머신 러닝은 인간이 미처 생각하지 못한 부분을 프로그램이
맨땅에 해딩해가며 사람과 다른 측면으로 생각할 수 있기 때문에
인공지능 기술의 핵심이라 할 수 있다.
3) 인공지능의 고등화
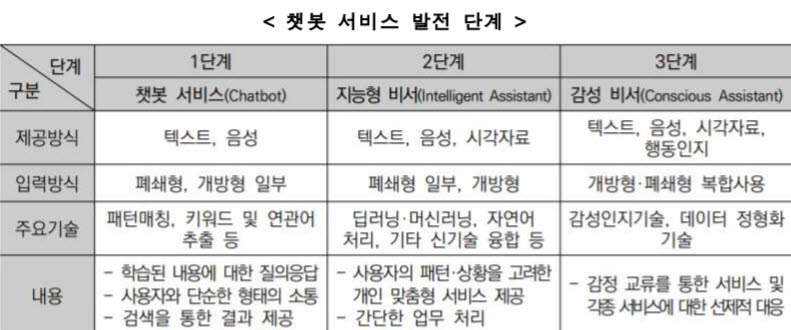
이미 대기업들은 이루다보다 더 고등적인 대화 구사를 위해
나쁜 말과 좋은 말을 구분할 수 있게 데이터를 조정하거나
전에 했던 말을 기억할 수 있게 하여 자연스러운 대화를 이끌어낸다.
이는 3단계 레벨에 도달한 챗봇들인데
3단계 챗봇은
- 다자간 채팅
- 챗봇 간의 의사소통
- 과거 담화 기억력
- B2B, 대화 청취기능과 대화 수행능력
- 자체 학습 능력
- 챗봇 대화 주도
- 지능적 API 탐색과 결과 도출
- 외부 정보망과의 링크
같은 특성을 지니고 있다.
-인공지능기술 기반 대화형 챗봇 개발 현황과 지능형 언어교육용 챗봇 개발 방안 김인석 ‖ 글로벌영어교육연구소 대표-
4) 이런 글에선 역시 미래 전망이 빠지면 섭섭하지
많은 사람들은 인공지능의 소프트웨어적인 방식에 좀 더 중점을 두고 질문한다.

인공지능의 생각이 인간을 뛰어넘을 수 있나요?

인공지능이 감정이라는 걸 가질 수 있나요?
모두 이론적으로 가능한 이야기이다. 하지만 아직은 윤리적 문제인
인공지능의 감정에 대한 것은 해소되지 못하였다.

하지만 지금은 소프트웨어보단 하드웨어의 한계를 극복해야 그런 서비스를 할 수 있다.
인공지능이라 해봤자 아직은 그저 '기계'이기 때문이다. 전기 끊으면 꺼지는.

3단계 챗봇같은 고등적인 인공지능을 챗봇을 통해 서비스하려면 엄청나게 돈이 든다.
어마어마한 연산능력을 요구하기 때문이다. 하지만 현재 GPU의 병렬연산으로는 한계가 있다.
이런 한계를 극복하기 위해 Google에선 병렬연산에 최적화된 새로운 회로를 만들었다.

바로 TPU(Tensor Processing Unit)이다. 기존 GPU 보다 100배 빠른 연산능력이 있다.
Google은 이 사기템을 세계로부터 숨기기 위해 특허도 내지 않고 자사의 클라우드를 통해서만 서비스할 수 있게 출시하였다.
Google은 알파고 이후로 세계로부터 AI 기술을 인정받았고 지금까지 AI 산업을 주도해오고 있는 것이다.
이 TPU 서비스를 통해서 Google은 개인도 고도화된 AI 서비스를 할 수 있게 발판을 마련한 것이다.
곧 대(大) AI 시대는 온다.
다음 포스팅은 Google의 TPU가 뭐고 얼마나 사기인지 알아보도록 하자.
'IT > 인공지능 AI' 카테고리의 다른 글
| 인공지능 환각 이해하기 (0) | 2023.07.19 |
|---|---|
| ChatGPT로 대화술 마스터하기 : ChatGPT - prompt engineering의 기초 (기본원리) (0) | 2023.06.08 |